Basic BGP
If you have to explain to someone new to the ISP
environment what Border Gateway Protocol (BGP) is, the best definition
would be that it's the routing protocol that makes the Internet work. That's because BGP it's a highly scalable routing protocol.. Because it carries the internet , it's a pretty important protocol, and it can also be the hardest one to understand.
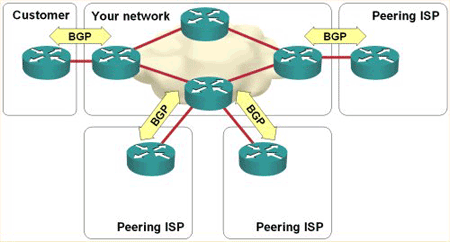
The Border Gateway Protocol makes routing decisions based on paths, network policies, or rule-sets configured by a network administrator and is involved in making core routing decisions.
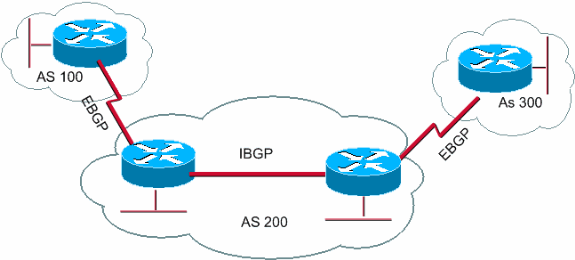
BGP may be used for routing within an autonomous system. In this application it is referred to as Interior Border Gateway Protocol, Internal BGP, or iBGP. In contrast, the Internet application of the protocol may be referred to as Exterior Border Gateway Protocol, External BGP, or EBGP

BGP should be used for one of these reasons:
- It’s the only routing protocol that can connect your organization to multiple AS
- If you need to implement a routing policy (path and packet flow manipulation) only possible with BGP
- If your organization is acting as a transit AS and connect others AS
Who needs to understand BGP?
BGP is relevant to network administrators of large organizations which connect to two or more ISPs, as well as to Internet Service Providers (ISPs) who connect to other network providers. If you are the administrator of a small corporate network, or an end user, then you probably don't need to know about BGP.BGP basics
- The current version of BGP is BGP version 4, based on RFC4271.
- BGP is the path-vector protocol that provides routing information for autonomous systems on the Internet via its AS-Path attribute.
- BGP is a Layer 4 protocol that sits on top of TCP. It is much simpler than OSPF, because it doesn’t have to worry about the things TCP will handle.
- Peers that have been manually configured to exchange routing information will form a TCP connection and begin speaking BGP. There is no discovery in BGP.
- Medium-sized businesses usually get into BGP for the purpose of true multi-homing for their entire network.
- An important aspect of BGP is that the AS-Path itself is an anti-loop mechanism. Routers will not import any routes that contain themselves in the AS-Path.

To connect to the Internet, an Enterprise uses either default routes (+ redistribution) or
BGP (require much memory and processing power).
BGP is the better choice when you have multiple route and you would like to manipulate these routes.
BGP is always used as the routing protocol of choice between ISPs (external BGP) but also as the core routing protocol within large ISP networks (internal BGP).
Outbound routing are routes that direct packets from Enterprise to Internet and inbound
routing are routes that direct packets from Internet to Enterprise. There are

Since BGP contains so many routes (the Internet), ISP gives you 3 options to receive
routes:
- Default route only: advertise only a default route to BGP
- Full update: ISP advertise the entire routing table
- Partial update: ISP send you some routes that would be shorter if reached from you and a default route for traffic that are better routed by ISP.

ASN ranges from 0 to 65,535. BGP assigns 64,512 - 65,534 ASNs to be private. Being
private means this ASN connect to only one other ASN (sometimes multiple ASN) and these
ASNs can’t cause loop by themselves.

Public ASNs are assigned by RIPE NCC and registered in RIPE database, private ASNs can be
removed on eBGP configuration by using ‘neighbor ebgp-neighbor-address remove-private-
as’ command.

BGP peering is establishing using TCP port 179. Using TCP, a TCP segment is resend is
retransmission timer reaches 0. The far-end acknowledgement may be delayed up to a 1
second to determine if any data should be sent along with the acknowledgement.
Because BPG uses TCP, it’s reliable and can perform error recovery. One of the is flow
control. Each BGP peer advertises its available buffer space to allow the far end of the
session to send only a specific amount of data to prevent overflowing.
Underlying TCP session can be shown with ‘show tcp brief’
Only one instance of BGP can be enabled in a router.
Path Attributes: AS_PATH
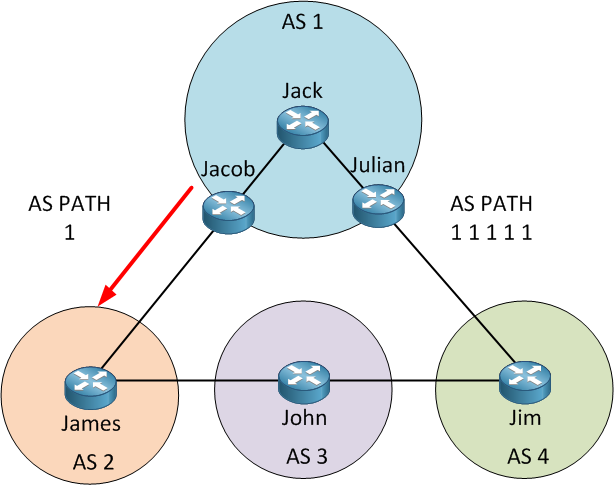
Path attributes (PAs) are factors that allow BGP to select a route over another. By default,
no BGP PAs have been set, and BGP use AS_PATH (autonomous system path) PA when
choosing the best route among many routes.
When a router uses BGP to advertise a route with AS_PATH, it will tell which list of ASN the
path will go through. AS_PATH can:
-
- Choose the best route by using the route with shortest AS_PATH
- -
- Prevent routing loops.
from ASN 3 then flow to ASN 7 then 9 and arrives at ASN 1, it will have an AS_PATH of (3,
7, 9). BGP, by default, choose the route with the least amount of ASNs (distance vector).
Loop is also prevented by ignoring route updates that contain the current AS’s ASN.
However, having duplicated ASN means ASN 3 can’t learn route to the duplicated ASN 3.
As we mention before ,BGP defines 2 kinds of neighbors:
- internal BGP (iBGP)
- and external BGP (eBGP).
This is used to refer to neighbors that are in the same ASN or different ASN.
One difference is the update of AS_PATH, when advertising to an iBGP peer, no ASN is
added. When advertising to an eBGP peer, this AS’ ASN is added. All BGP connection can be
listed as either iBGP or eBGP.
Types of routing
There are 2 types of routing:- Hot-potato routing: traffic exit the AS via the closest exit point.
- Cold-potato routing: traffic exit the AS via the path closest to the destination. Optimal.
BGP FSM
BGP finite state machine (FSM) works as:- Router try to establish TCP connection with IP address configured in ‘neighbor’ command at well-known TCP port 179.
- After 3-way handshake is complete, first BGP message send is the Open message, which contains parameters to be verified to establish neighborship.
- After parameters match, and neighborship is formed, neighbors are in established state. Then Update messages can be send, which includes list of PAs and prefixes.

We have a graphic for a better understanding:

To verify neighborship, use ‘show tcp brief’ can display the underlying TCP connection. ‘debug ip bgp’ display intermittent BGP information.
‘neighbor IP_ADD shutdown’ command shut down the BGP neighbor and move the routers to Idle state.
Here are the 4 types of message send:

All BGP messages share the same header, composed of:
- 16 byte marker field: set to all 1s to detect a loss of synchronization.
- 2 byte length field: indicate total length of BGP message, range from 19 to 4096
- 1 byte type field: indicate different BGP messages in () in above table.
All prefixes, except those filtered by ‘neighbor IP_ADD route-map NAME in’, are listed in the routing table for calculation.

eBGP neighborship
To configure BGP, you need at least 2 commands:- ‘(config)#router bgp ASN’
- ‘(config-router)#neighbor IP_ADD remote-as REMOTE_ASN’
For BGP neighbor relationship to form,
- TCP connection between them MUST be established and both routers MUST have ‘neighbor remote-as’ to refer to the IP address of the interface for which TCP packets exit (when the exiting interface is not explicitly defined).
- The neighbors MUST be listed in ‘neighbor IP remote-as ASN’ command
- BGP RID MUST not be duplicated
- Md5 authentication MUST pass (if configured)
BGP RID is established by
1) configuring ‘(config-router)#bgp router-id RID’. If not,
- Use the highest numeric IP address of any up/up loopback interfaces at BGP initialization
- Use the highest numeric IP address of any up/up normal interface at BGP initialization
When multiple links exist between 2 BGP routers, and you would like to establish BGP neighborship between them, there are 2 options:
- configure a connections for each physical interface; consumes bandwidth and memory.
- Configure connections using virtual (loopback) interfaces, which requires less bandwidth and memory and ensure the interface is always up/up.
- ‘(config)#interface loopback NO’ -> ‘(config-if)#ip address IP_ADD’
- ‘(config-router)#neighbor IP_ADD remote-as ASN’, note that this is still the neighbor’s IP address
- Tell the router it’s using a loopback interface by ‘(config-router)#neighbor IP_ADD update-source loopback NO’ where NO is the number configured in ‘interface loopback’. Now, you have specified the destination address and the source address of this neighborship.
- Make sure router has IP route to its neighbor’s loopback interface (usually through a physical interface by static route or IGP; remember to allow redundancy)
- Configure eBGP multihop with ‘neighbor IP_ADD ebgp-multihop TTL’ command. This command allow you to define the TTL field, which is default to 1. When sending segments directly between the 2 interfaces, this command is not needed. However, when using loopback interface, TTL decrease by 1, thus, the segment is discarded before it reaches the loopback interface. Configuring the value to 2 solves the problem.
Using a loopback interface solves 2 problems:
- If the connected port is down, the router can still send the packet without being interrupted because loopback interface is always up.
- If the connected port is down, and another interface tries to reach the neighbor will be banned because the source address doesn’t match.
The ‘neighbor’ command can be configured with ‘peer-group’ parameter, this allow one set of command can be applied to all neighbors (either external or internal, not both) joining the peer-group; thus, simplify configuration and reduce updates. ‘neighbor NAME peer-group’ set a peer group with NAME, then ‘neighbor IP_ADD peer-group NAME’ can assign that neighbor to that peer-group, note that neighbor must have ‘neighbor remote-as’ set.
Network command
Be default, BGP uses ‘no auto-summary’ command.BGP’s ‘network PREFIX mask SUBNET_MASK’ command cause the route stated to match any routes from the list of prefix/length received; the match MUST be exact. If a match is found, the route is put into the local BGP table.
Note: this prefix MUST be a public address range.
If you have several subordinate routes instead, you need to use manual summarization or static route with null0 exit interface.
If you omit ‘mask’ parameter, you get a classful network.
If you use ‘network’ command without ‘mask’ and ‘auto-summary’ is also used, the route will match:
- An exact route found in the routing table, OR
- Any subordinate routes
However, if you have multiple subordinate routes instead, you need to use ‘route-map’ parameter to include a prefix-list or ACL to match the range of routes you would like to advertise. You can find them at ‘show ip bgp IP_ADD/CIDR longer-prefixes’ command.
Nevertheless, if you have multiple subordinate routes that you would like to summarize and advertise as a single route, you can:
- Use IGP summarization to create the route from the entire prefix
- Configure null0 static route for the entire prefix on the Internet-connected router
- Configure BGP route summarization by ‘(config-router)#aggregate-address IP_ADD MASK [summary-only][as-set]’ command. Using ‘summary-only’, the subordinate routes will be suppressed of advertisement and they will show ‘s’ as their designation. Using ‘as-set’, all the AS passed will be recorded. A ‘null0’ exit interface is also recorded
iBGP neighbor relationship
Sometime, the iBGP neighbors won’t be in the same subnet due to their distance. At this time, it’s recommended that you use loopback interface. The configuration is the same as for eBGP except there is no restriction of TTL = 1 in iBGP neighbor relationship.
When iBGP neighbors are directly connected, it only requires ‘neighbor remote-as’ and ‘route bgp’ command to form the neighborship.
BGP:
1) advertise best route (with influence from the PAs) in Update message,
2) don’t advertise iBGP-learned routes to iBGP peers (only external routes are advertised to iBGP peer to prevent loops). Only the BGP router that has the external route will advertise the external route, this prevents a BGP router from advertise the route back to where it come from.
In BGP, the next-hop router doesn’t have to be in the same subnet as one of the router’s IP address (e.g loopback interface); because BGP is not designed to work under this condition.
Next-hop IP address is not changed in Updates. If R1 (ASN 1) advertise to R2 (ASN 2) with its loopback interface, and R2 advertise the route to R3 (ASN 2), the next-hop address will still be the loopback IP address of R1. This situation would not cause any problem as long as each router has an IP route that matches the next-hop IP address.
The above solution is provided by having a route (static or dynamic) to the destination.
Another solution is by using ‘neighbor IP_ADD next-hop-self’ command on both routers in a neighbor relationship so the next-hop IP address change as needed. This way the router would know how to forward the message. A drawback to this solution is the loopback interface addresses, which also require a static or dynamic route to it for packets to be forwarded.
When advertising BGP routes for BGP routers not connected together, you may ran into loops.
To prevent BGP loop (in CCNP), you can use:
- Run BGP on some internal routers. Since BGP block internal routes from advertising back (so the route learning is just one way), one path will not allow other routers to learn. You need a full mesh design for it to work.
- Redistribute BGP routes into IGP (not recommended). Due to the large amount of routes to be processed in BGP, redistributing a default route and calculating the metric will be a big task and requires a lot of memory and processing power; it may even crash your device.
Sync is performed by ‘(config-router)#synchronization’ command.
In later versions of IOS, this feature is off by default because redistribution between IGP and BGP is not recommended. However, when BGP is implemented with MPLS, such implementation is considered reasonable. Sync should also be turned off if
- All routers in the AS are running BGP
- All BGP routers inside AS are meshed
- When AS is not a transit AS.
BGP filter

BGP can filter Update message per neighbor, and disable the filter by ‘reset’ command. BGP can filter on prefix/prefix length, PAs, direction, and most importantly, per neighbor. IGP often use one ro

One reason to use filtering is to prevent the Enterprise AS from becoming a transit AS for which packets from one ISP to another should not have routed from.
Outbound routes refer to routes from which packets from outside come in. Inbound routes refer to routes which packets send from this router to the outside.
‘show ip bgp neighbor IP_ADD advertised-routes’ can be used to check if route is implemented.
For any changes can take place, you must use ‘clear ip bgp IP_ADD’ which is the IP address of the neighbor; this command can perform a hard or soft reset. Other methods include reloading the router and administratively shutdown a neighbor.
A hard reset occurs when the local router 1) bring down the neighborship, 2) the underlying TCP connection, 3) remove all BGP table entry learned from that neighbor.
A soft reset occurs when 1) router doesn’t bring down the neighborship or TCP connection, 2) resend adjusted outgoing Updates, which then adjust the BGP table.
A hard reset could
- take a long time to complete and interrupt routing in the interim
- Count as a flap and cause peers to disassociate themselves
- Force a full set of routing updates and could generate a lot of traffic.
You can verify the command by
‘show ip bgp neighbor IP_ADD received-routes‘ (pre-filter) -> require ‘neighbor IP_ADD soft-configuration inbound’
‘show ip bgp neighbor IP_ADD routes’ (post-filter) and ‘show ip bgp neighbor IP_ADD advertised-routes’ (advertised in Update)
To see pre-filtered BGP table, use ‘show ip bgp’ command
Only extended ACL is can filter prefix/prefix length
BGP PA
You can define many BGP PAs to adjust the path selection process, different PAs set different criteria.Next_Hop PA defines the next-hop IP address of a route. Here are some PA:
Here is a general process of how BGP chooses its route. Step 9 - 11 is only used when there is a tie, or the previous step can’t generate a clear winner.

Step 1, 2, 4, and 6 influence the outbound routes.
Step 1, or Weight is not a BGP PA, but a Cisco feature. Weight can be selective, pre-configured (per route, per neighbor, on the neighbor) to influence route selection process; the biggest weight route is chosen. Weight can’t be learned through Update because no such field is included. Weight value range from 0 to 65,535, 0 for learned routes, and 32,768 for locally injected routes.
This is applied to all learned or injected (‘network’) routes (coming in, then leaving the router) specified by ‘neighbor IP_ADD route-map NAME in’ (apply route map to particular routes from particular neighbor), then ‘set weight’ followed by the weight.
You can also set all weight values to all routes from one neighbor by ‘(config-router)#neighbor IP_ADD weight VALUE’ command.
Step 2, or Local_Pref PA is used to determine the best router (in the AS) to forward packets that belong to a certain prefix. For instance, if R1, R2, and R3, belong in ASN 2 and only R2 has external route to 192.1.1.0/25, while R1 and R3 learned this route from R2. In this case, R2 can set its Local_Pref so that it becomes the favorable router for packets to 192.1.1.0/25.
By design, Local_Pref is set on R2 (using route-map) and then updated to R1 and R3 via iBPG Update. Local-Pref is NOT updated to eBGP peer by default.
Local_Pref has default value of 100, whereas it ranges from 0 to 4,294,967,295, with higher values more favorable. The default value can be changed by ‘(config-router)#bgp default local-preference’ followed by the value.
This PA can also be set for a particular set of routes specified in the ‘neighbor IP_ADD route-map NAME in’ command then ‘set local-preference’ subcommand, where the neighbor
is the eBGP from the ISP. This is because Updates for eBGP connection will not include Local_Pref value.
‘show ip bgp IP_SUBNET/CIDR longer-prefixes’ show which route is older by placing its entry later.
Before the best BGP route is placed into the routing table, it still has to go through the IOS Routing Table Manager (RTM). This is where AD comes into play, with eBGP having AD of 20 and iBGP having AD of 200.
Step 4, AS_Path can be increased so that the route becomes less favorable to forward packets through. This is done by a neighbor route map followed by ‘set as-path prepend’ followed by the ASN. If you would like to add 2 ASs, each has ASN 3, you can use ‘set as-path prepend 3 3’. It’s recommended that you use the same ASN as that of the current AS to prevent confusion.
‘show ip bgp rib-failure’ shows routes for which BGP has chosen the best route, but not listed in the routing table (which is also known as routing information base, or RIB). This can occur when BGP chooses its best route, but it’s not placed into the RIB because there is another routing protocols presenting the same prefix and has a lower AD.
BGP also has ‘maximum-paths’ command that allow tied routes (after step 8) to be presented in the routing table. The number designate how many routes will be allowed.
To control inbound routes, you can use multi-exit discriminator (MED).
The Enterprise can announce to the ISP a value (MED) that tell ISP which route to the Enterprise is the best. The smaller the MED, the more favorable the route. This often occurs when there are multiple routes. MED is set with ‘default-metric VAL’ command.
iBGP routes within the AS decides which route (best) will accept traffic from the remote AS. The range of MED is the same as Local_Pref, but the smaller, the better. This criteria is set by ‘set metric’ in a outward route map.

Basic BGP
 Reviewed by ohhhvictor
on
2:37 PM
Rating:
Reviewed by ohhhvictor
on
2:37 PM
Rating:





















Nice article! p.s its possible to get this article in pdf format?
ReplyDeleteHello Janis..
DeleteI studied a little bit about this topic from different places .. and made this article.
This whole article wasn't made before me publising it, so there is no pdf format of it for sure.
My suggestion is that you try to copy the article somewhere..and them convert that document to pdf.
Regards..
Victor
Good piece
ReplyDelete